Some of the earlier tasks I work through when assessing a web application revolve around enumerating the available attack surface my target has to offer. There are a few easy ways to quickly find paths offered by an application.
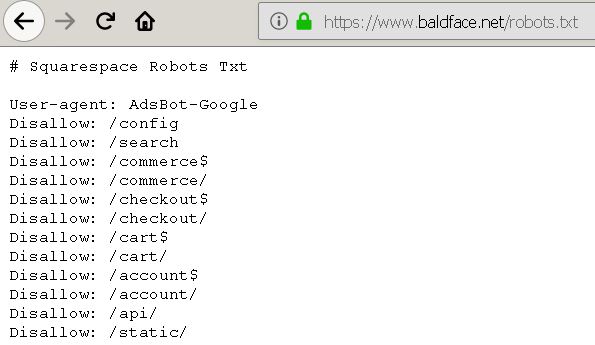
robots.txt
The first of these would be examining the ‘/robots.txt‘ file a site may happen to be employ. The robots.txt file, also known as the robots exclusion protocol or standard, is a text file that tells web robots (most often search engines) which pages on your site to crawl. It also tells web robots which pages not to crawl. At the end of the day, I don’t really care an awful lot about the syntax or functionality of the file. I just want to catalog the paths listed within in it.
Accessing ‘/robots.txt’ in your favorite user-agent may provide you with helpful, preliminary information about your target.
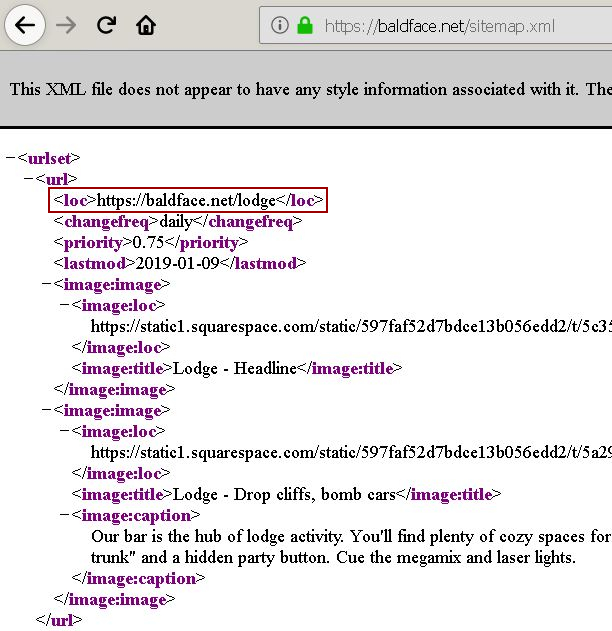
sitemap.xml
And just like robots.txt, I also attempt to access my target’s ‘/sitemap.xml‘ file. Sitemaps are a protocol that help site owners inform major search engines about URLS on a website that are available for crawling. Basically, a sitemap helps search indexers discover content on an application they might otherwise miss during an unassisted crawl.
Accessing ‘/sitemap.xml’ in your favorite user-agent may also provide you with preliminary information about your target.
Apple App-Site Associations
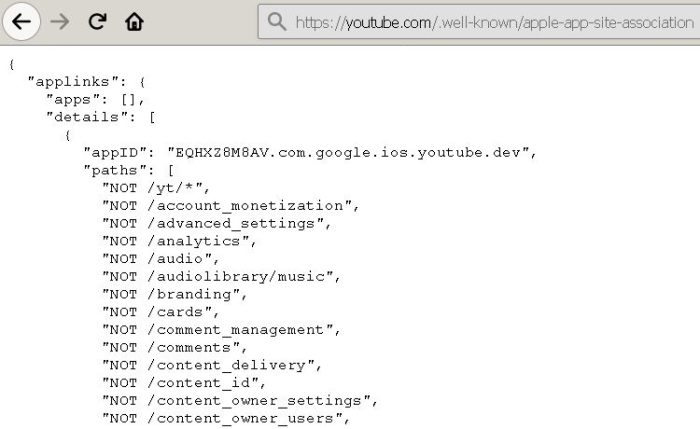
In the same vein as sitemap.xml and robots.txt is the Apple App-Site Association file. The ‘/.well-known/apple-app-site-association‘ file associates a website’s domain with a native iOS app. In other words, it’s a safe way to prove domain ownership to Apple. Most web applications won’t feature an AASA file but it’s worth checking. The included paths could prove helpful on an engagement.
An AASA file looks something like the following.
Google Enumeration
There are all kinds of ways to leverage Google dorks to help dig up information about your target web application. I’m a big fan of using the simplistic ‘site:‘ dork and grabbing everything Google has to offer on my target. Simply search on something like “site:www.domain.com” to retrieve all of the URLs Google has associated with your target. This ends up looking like the following.
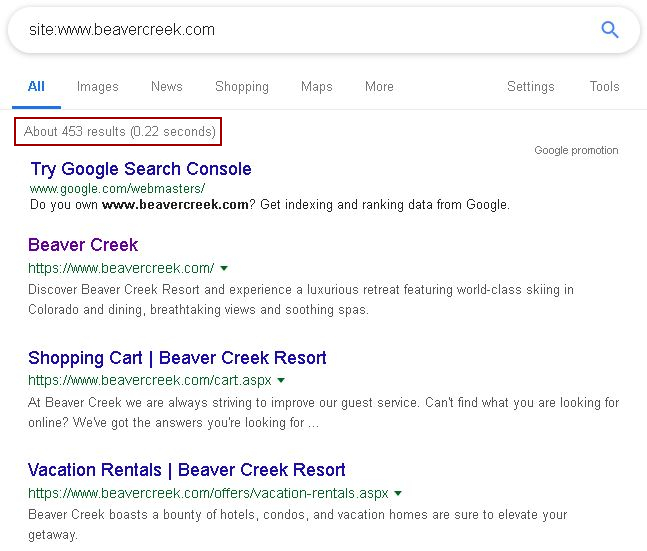
As you can see from the screenshot, this can turn up a large number of results. As such, I like using the command line tool known as ‘Googler‘ to automate these searches. I definitely recommend looking into it.
Bing Enumeration
I employ the same exact dork used for the above-mentioned Google search when querying Microsoft’s “Bing” search engine. I have not found a good command line tool to automate this and have resorted to signing up for Azure services to make use of their free “Cognitive Services – Web Search” API. Once an API key is obtained, it’s just a curl command to iterate through the results. This ends up looking like the following.
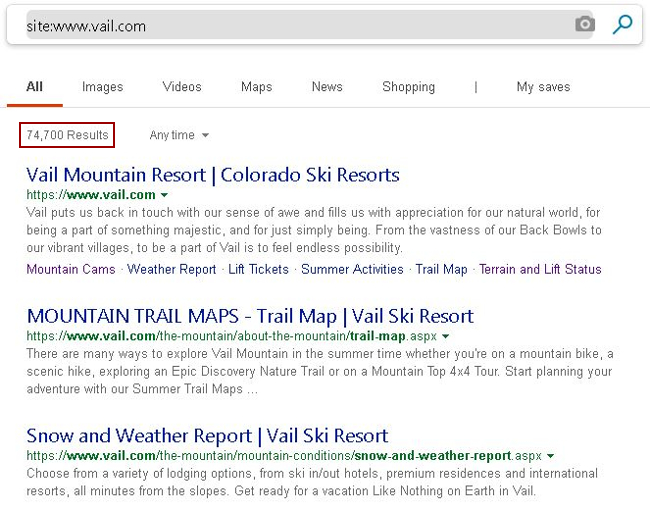
Again, this can yield a large result set. I definitely recommend working with an API key when such a large number of hits is returned.
Wayback Machine
And lastly, I like to hit archive.org‘s web history search engine to see if I can unearth some old paths long forgotten and possibly unlinked from the main UI. I usually navigate to their URL listing found by accessing the “Summary” link and then hitting the “Explore www.domain.com URLs” link. The URL used to access this listing ends up looking like “https://web.archive.org/web/*/www.domain.com/*“. An example of the output looks like the following.
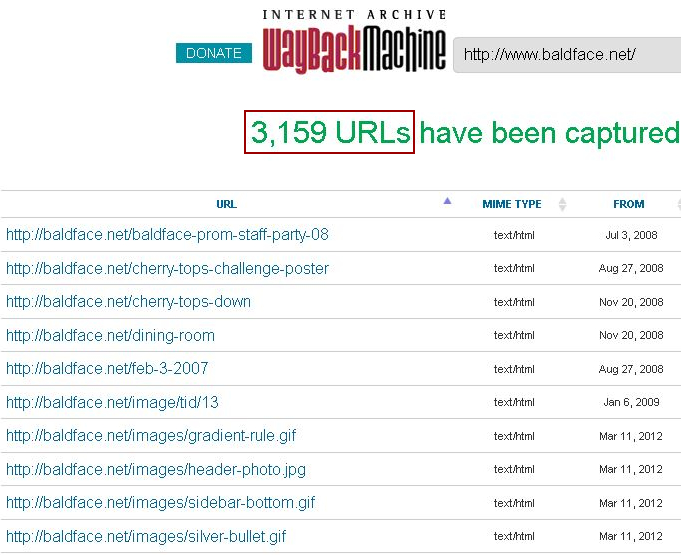
Again, this can output a large amount of information. Running a search through Burp proxy will yield a call to their API which can make grabbing this output much easier. Look for a call to https://web.archive.org/cdx/search when working through this exercise.
That’s about it for low-hanging application recon fruit. Hopefully these quick and dirty tips will help you discover content during the earlier phases of your engagements.


