Something I like to do when testing a web application is to look for sensitive files that have been placed in web-exposed directories. Application administrators sometimes leave files in places they shouldn’t that contain information which may help advance your attack chain. Source code, configuration files, and even text-based databases can be found left in web directories. They may not be directly linked to by the target application but with a little sniffing around, you might be able to uncover something valuable.
With that said… I compiled a list of file names and extensions that, when combined, might be of use if found exposed by an application server. You can download these files at the following links:
I plan to actively curate them as they will certainly change over time. You can put them together using something like the following:
#!/bin/bash
BASE="/usr/local/scripts"
BASES="${BASE}/wordlists/custom/web/web_configs.txt"
EXTENSIONS="${BASE}/wordlists/custom/web/web_extensions.txt"
cat $BASES | while read BASE; do
cat $EXTENSIONS | while read EXT; do
echo "${BASE}.${EXT}"
done
done
You’ll want to fine-tune your final list to reduce the number of requests made to your target web-server depending on what technologies you’re working with. An example might be:
grep -v -e '\.php' -e '\.do' -e 'wp' -e 'wordpress' wordlist.txt > wordlist.new.txt
I often use the resulting list in combination with the discovered web directories my testing efforts have turned up. I do this by exporting the list of accrued URLs contained in my Burp project site-map and massage the results until they look something like the following.
Let’s say I’ve discovered the following directories during my testing efforts:
- foo/bar
- powder/is/life
- must/have/bbq/now
- boof
I run this list through a script that spits out every possible discovered directory contained on the server. Something like the following.
#!/bin/bash
INPUT="$1"
cat $INPUT | while read LINE; do
IFS='/' read -r -a ARRAY <<< "$LINE"
COUNT="${#ARRAY[@]}"
COUNT=$((COUNT - 1))
if [[ $COUNT -eq 0 ]]; then
echo "${ARRAY[0]}"
else
for((i = 0; i <= $COUNT; i++)); do
PATH=""
for((j = 0; j <= $i; j++)); do
if [[ $j -eq 0 ]]; then
PATH="${ARRAY[$j]}"
else
PATH="${PATH}/${ARRAY[$j]}"
fi
done
echo $PATH
done
fi
done | sort -u
And the resulting output after feeding it a list of discovered directories would be:
boof foo foo/bar must must/have must/have/bbq must/have/bbq/now powder powder/is powder/is/life
Now you have a list of web directories to check for various hidden files that may be of interest if discovered.
I’ll often configure an intruder attack that fires off HEAD requests looking for the targeted files. Note that the number of requests gets very large very fast!
The intruder request would look something like the following (note the payload positions).
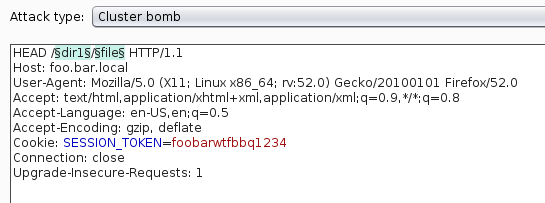
The directory list would be the first payload. You may want to add a URL decode payload processing rule.
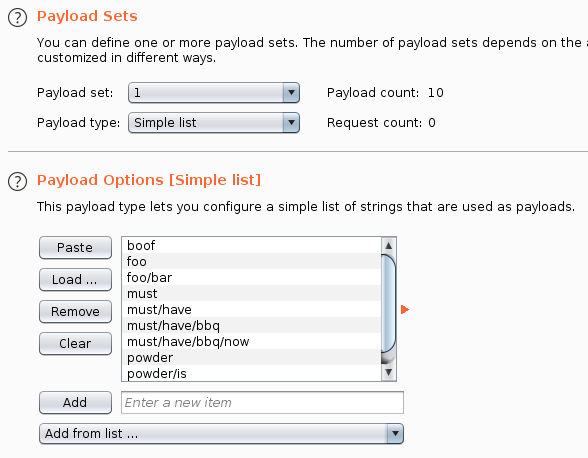
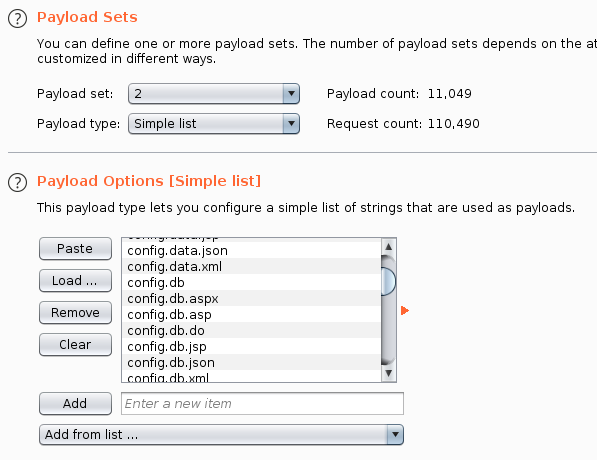
The file list would be the second payload. Again, you might want to add a payload processing rule to prohibit the payload from being URL encoded by Intruder.
And then you examine the attack results. You’d want to sort by status code or file size to quickly determine if anything has been discovered.
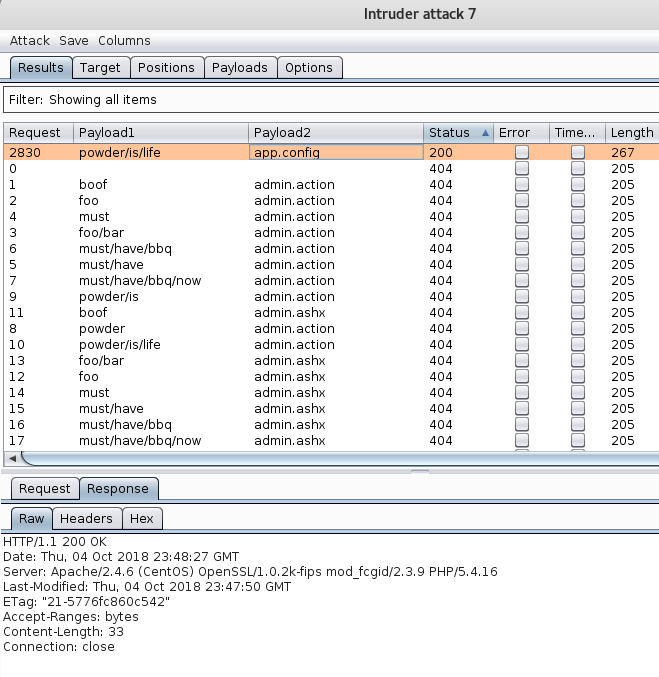
In my proof-of-concept I was able to discern a single file (/powder/is/life/app.config) of note via difference in status code. The file size was slightly different, as well.
So next time you’re banging away on a web application remember to test the admins’ operation-security by looking for lazy mistakes that may entail exposing sensitive information. Humans are lazy and shit happens.
Happy hunting!


